Reasoning models achieve impressive performance on standardized benchmarks (AIME, MATH500, GPQA), yet show deficits in robustness and generalization on simple problems. We observe that when these reasoning models are confronted with small changes within the same problem, their performance can vary greatly. We study this phenomenon by testing models on Alice In Wonderland.

Alice in Wonderland (AIW) uses simple problem templates with 6 natural variations, resulting in very similar problem instances. These problems are significantly easier to solve for humans than problems found in popular reasoning benchmarks like AIME2024, but current reasoning models still struggle and are sensitive to variations.
We test reasoning models on 3 sets of AIW problems (AIW Friends, AIW Plus and AIW Circle Colleagues), each containing 6 variations of the same puzzle template.
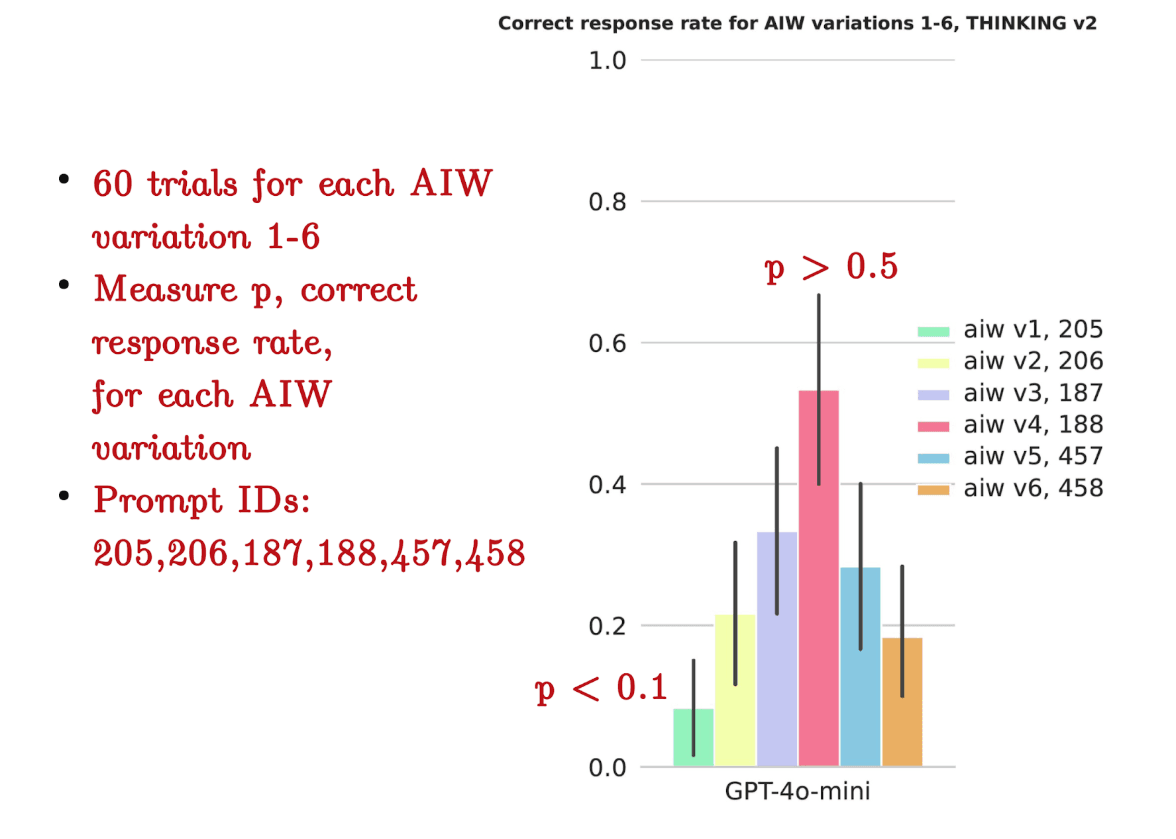
Non-reasoning LLMs struggle significantly on these problems. Testing GPT-4o-mini on AIW, we see low performance and high variance in accuracy across different problem variations.
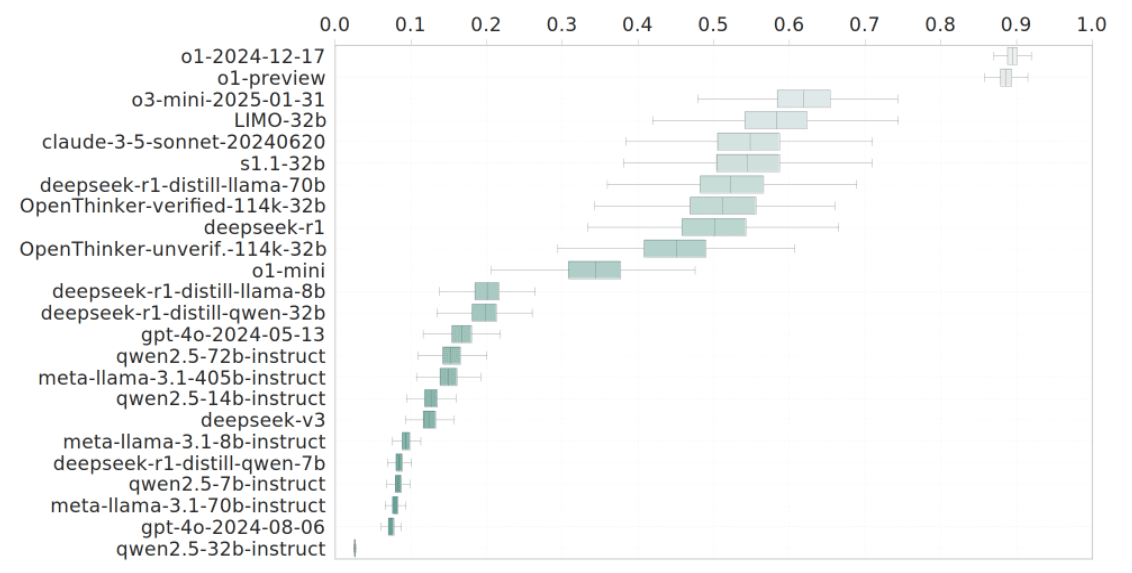
Reasoning models can achieve higher average accuracy than traditional LLMs on AIW. o1 and o1-preview achieve the highest accuracy, but DeepSeek R-1 and the larger distilled reasoning models perform better than o1-mini. Surprisingly, these larger distilled reasoning models also perform equally or better than the full DeepSeek R-1 model on the AIW tasks.
We also observe large variance due to fluctuation across problem variations, showing robustness issues even for high performing reasoning models. o1 and o1-preview, the highest performing models, show much better robustness.
Below, we show this variance across problem variations in greater detail by visualizing correct response rates with different colors for each of 6 variations of AIW Friends. Open reasoning models and o1-mini fluctuate much more than o1-preview on different problem variations. Large scale non-reasoning LLMs (Llama 3.1 405B and DeepSeek v3 671B) have very low correct response rates overall.
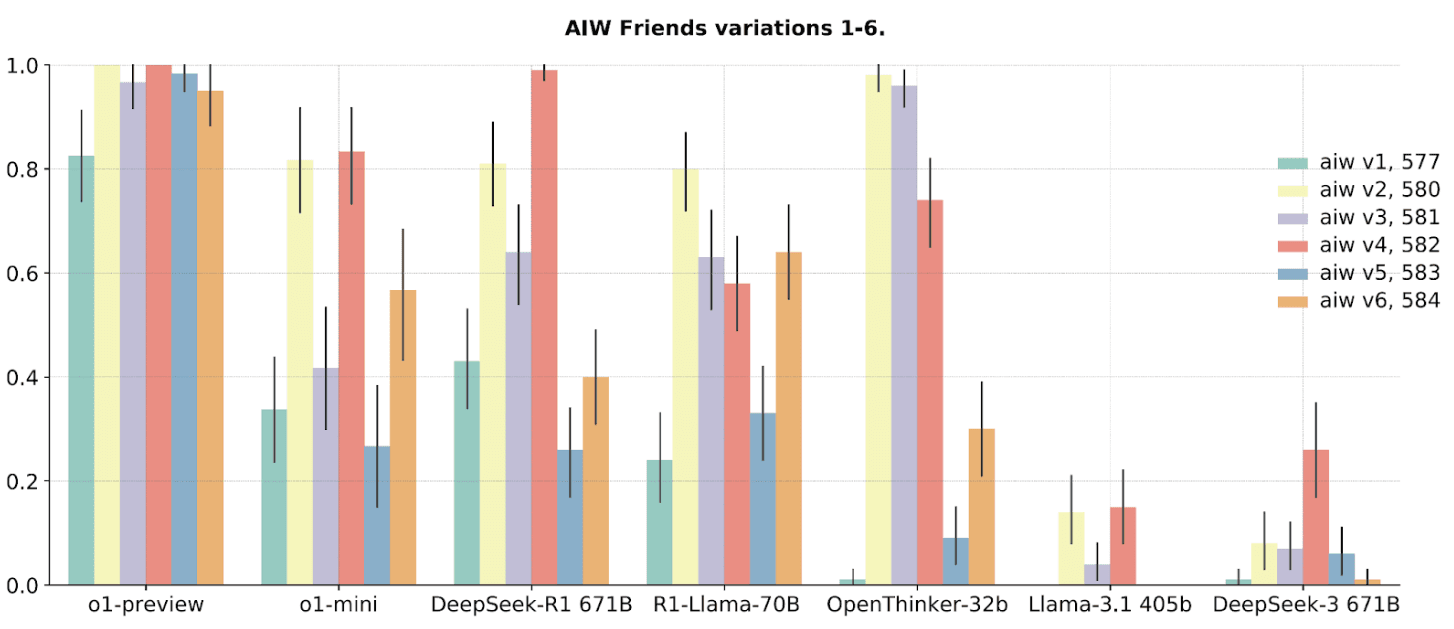
In summary, we observe that open reasoning models have a severe lack of robustness to the simple reasoning problems found in Alice in Wonderland. This deficiency is not currently captured by the standard benchmarks (AIME, MATH, GPQA) used to evaluate reasoning models. There is more work to be done to close the gap between the best open and closed reasoning models.